
An Error Alerting System of One's Own

This blog post was originally published on January 23, 2019 on the BulkWhiz tech, business, and operations blog, Whizardry, here.
“Software engineering is strewn with the wreckage of those who have relied beyond reason solely on the error alerting configurations of others.”
— Virginia Woolf, paraphrased
Picture this. It’s 5PM on a Saturday. By some twist of fate you do not yet completely understand, you’ve ended up both on call and committed to a family dinner at this ungodly hour of the Sabbath. You think it’ll be fine; you’ll just keep your laptop handy and periodically check your phone for error alerts until you safely ride out your on-call time slot. Right?
Fast forward to 6:07PM. You’re sprawled on the floor of your grandma’s bedroom, both laptop and phone open to your Slack alert channels and a shell on a production machine running, all on mobile data. Some production issue has vital services down and alerts that all look the same rolling in every millisecond. Your product manager is going crazy, and you yourself can barely breathe, let alone figure out what’s wrong and fix it. You start ruing the day you went into software engineering and wondering if pyramid schemes really are the scam they very obviously are.
Alerts, alerts, alerts
Before you call your friend who pitched you the latest Ponzi, know it doesn’t have to be that way. As hyperbolic as the above hypothetical situation is, it captures the essence of a very real software engineering problem: on-call fatigue. Yes, it’s great that you have an error monitoring system in place and that you’ve linked it to your workplace messaging app, but constantly seeing alerts that all look the same coming in at a huge frequency is just overwhelming. As time goes on, stress and burnout build up within the engineering team, production environment deviance becomes normalized, and issues are either unresolved or resolved very inefficiently.
Because of this, we decided to personalize our error alerting system. We narrowed down the problem into three major sub-problems:
- alerts weren’t being routed to the concerned team members,
- there was no way to differentiate between them at a glance, and
- they had too little helpful information.
We use Errbit, an open-source Airbrake-API-compliant error catcher that, like our own BulkWhiz API, is written in Ruby-on-Rails. Errbit supports a number of notification services (and, as per the essence of this post, you can always extend it to support even more), but we use Slack so that’s what I’ll focus on here.
To get started, we forked the Errbit repo on GitHub, created a Docker image and pushed it to DockerHub, initialized a test Errbit Kubernetes deployment pointing to that image and routed staging alerts to it, and we were good to go!
Don’t @ me — but actually @ me
What if you didn’t have to worry about every single alert ever but only the ones you were mentioned in? No more keeping tabs on the alerts channel for a good half hour after pushing production changes or analyzing a backtrace to figure out which fellow team member to tag. Our first thought was: Create a routing system within Errbit that gets git blame information from GitHub’s GraphQL API. Map the returned JSON to the in-app files and line numbers in the error’s backtrace and you have the GitHub usernames of the code authors. Map those to their corresponding Slack user IDs which you can get from the Slack API, either by getting them from Slack’s API method testing interface and passing them in an environmental variable to your Errbit deployment or, cleaner and more robust to changes, calling Slack’s API from inside your Errbit code.
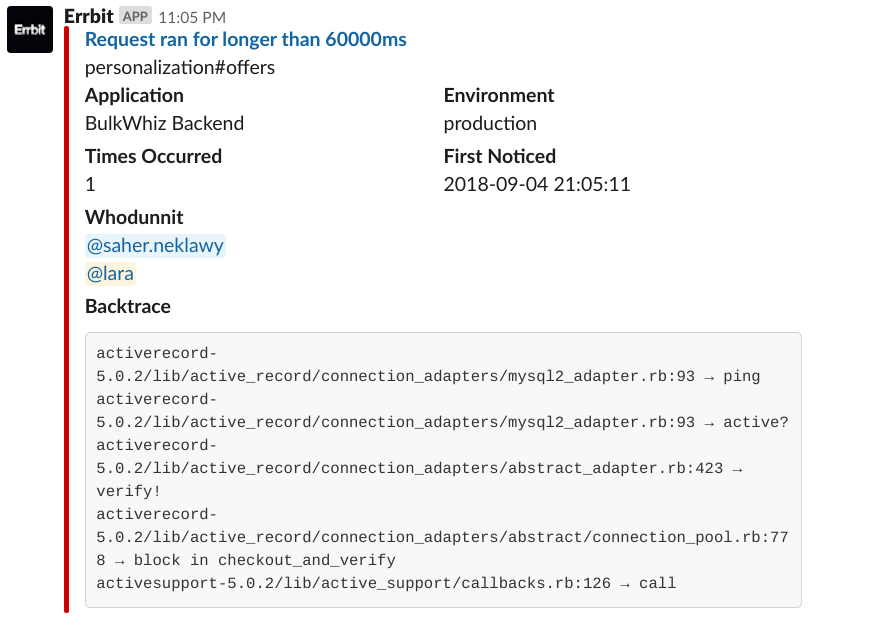 One of our first alerts with code author mentions. In the code, this is how the mentions work:
One of our first alerts with code author mentions. In the code, this is how the mentions work: "<@#{slack_user_id}>".
Now that’s all good and well, but “whodunnit” isn’t necessarily “whogottadealwithit.” As such, we implemented a force-assignment system, mapping certain error classes to the Slack user IDs of the responsible team members and checking that hash first before sending the git blame request. We thus had to create some custom error classes from our BulkWhiz API codebase to be able to raise those force-assigned errors where needed. Force assignment also proved useful in situations where the code author was no longer part of the team, or where the error at hand was a broader issue that more than one team member needed to deal with. In those cases, we decided to tag Slack user groups instead of individual users. (Pro tip: Slack user group mentions work a bit differently:
"<!subteam^#{slack_user_id}|#{slack_user_name}>".)
Triage and error
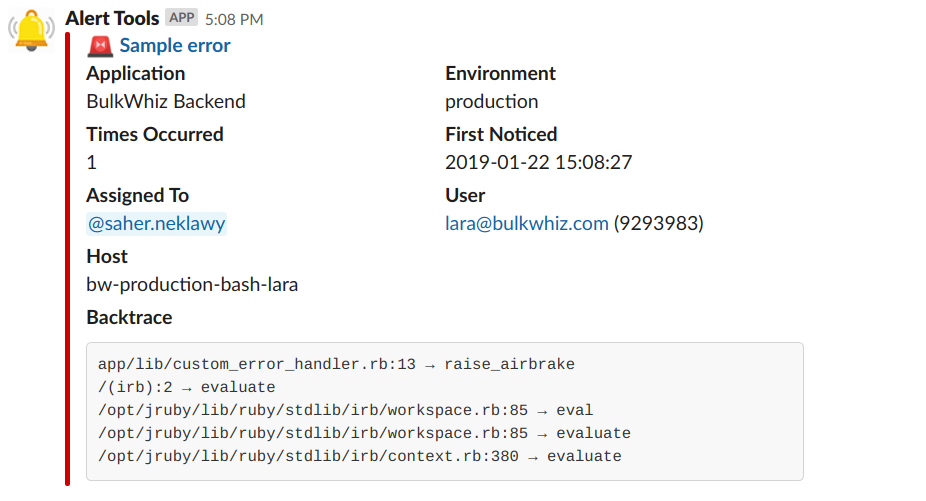
To make processing alerts even faster, we needed to begin differentiating between their levels of severity at a glance. Some alerts are actually uncaught exceptions, whereas others are notifications we manually raise from the BulkWhiz API codebase to trigger certain actions, both automated and human. Using color coding and emojis, we’re now able to visually differentiate between those two alert types at first sight.
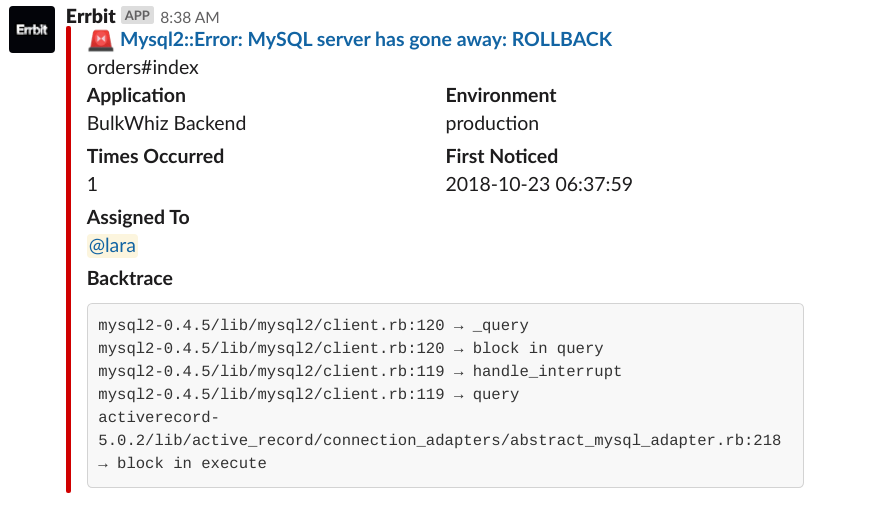
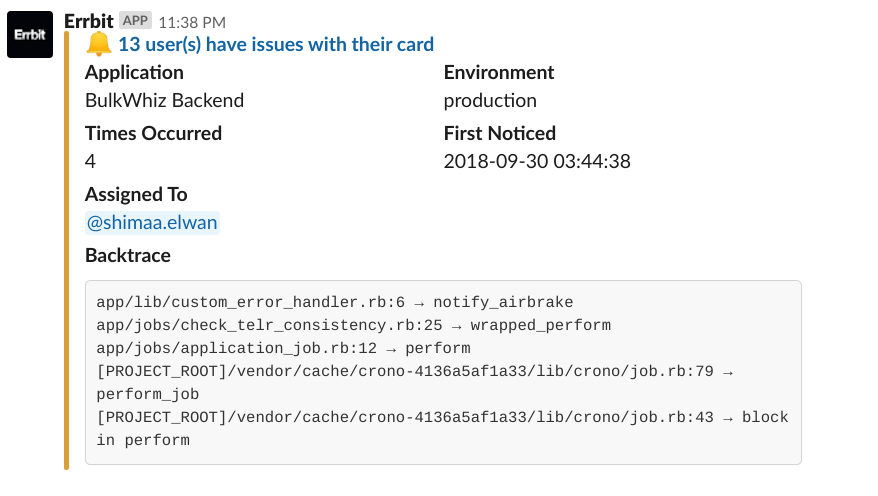 Exception versus notification. For notifications that do not have force assignments, we refrain from falling back on mentioning code authors to avoid unnecessary noise. (On a side note, notice how “Whodunnit” became “Assigned To”?)
Exception versus notification. For notifications that do not have force assignments, we refrain from falling back on mentioning code authors to avoid unnecessary noise. (On a side note, notice how “Whodunnit” became “Assigned To”?)
You’ll notice by looking at the “Environment” key that all these are production errors. In the beginning, I mentioned that we had set up a sandbox environment using staging errors. That’s another way in which we triage errors: Configuring our app to send production and staging alerts each to a separate Errbit deployment, both of which pull the same image (or different branches of that image if we which to test code changes first) but send alerts to separate Slack channels. To further filter out the most severe and urgent of errors, we then use an automation engine called StackStorm to send those alerts to a third Slack channel. That way, we can tell which alerts require immediate attention and which can wait.
Knowledge is power*
But only when you have the right parts of it — and the affected user is one of those. The Airbrake API already includes that information in the context key of the Notice object it creates on catching an error. This is unfortunately lost when you manually send a bare error to Airbrake/Errbit, so make sure you wrap your error in a Notice object first.
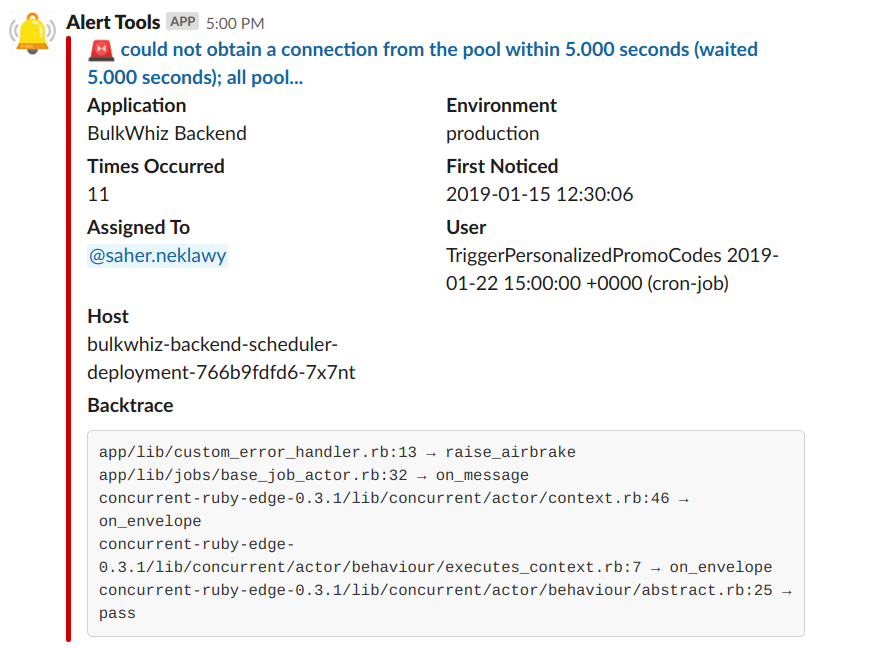
 Cronjobs are users too!
Cronjobs are users too!
Sending the hostname, a detail already captured by Airbrake/Errbit, to Slack is also a good way to be able to quickly tell where the problem is, especially in a Kubernetes cluster where one pod or node could be down or where you could be routing certain requests to certain pods.
Smarter, better, stronger
We set out to customize our error alerting system with three goals:
- to reduce noise,
- to streamline triage, and
- to enhance the information sent.
While the above configurations have helped us make tremendous strides towards reaching these goals, they can also be improved upon in future iterations.
Having a smarter routing model that mentions the author of the latest change in the backtrace, rather than all authors in the backtrace, would further reduce noise, as would having alerts fire once per error and instead periodically notify that the error is still occurring rather than flooding the Slack channel with alerts. In addition, adding a UI component to the alert where team members could rate the severity of the alert and then filtering based on that would improve triage by crowd-sourcing judgment calls about errors’ urgency.
Regarding the way we have deployed the system, there’s an argument to be made that using Errbit to send notifications is a violation of separation of concerns and that that is a job better suited for a customized bot built on something like Hubot, for example (which, interestingly, Errbit supports as a notification service).** Maintaining an Errbit deployment per environment would also result in unnecessary overhead if we wanted to monitor more than two environments, prompting us to question whether there is a better way to separate alerts from different environments.
Nothing is the same in practice as it is in theory. As users interact with your app, problems will occur, and you will need to be notified of them. The key is finding the means of notification that best suits your app, team, and workplace routines — and that doesn’t leave your engineers crying on their grandmothers’ bedroom floors.
The GitHub repo for this customized Errbit is publicly available here and the Docker image here. A pull request to the upstream Errbit repo is in the works.
Notes:
* The features in this section were implemented by Saher El-Neklawy, who is also the brains behind the other feature ideas and the deployment scheme.
** Special thanks to Ihab Khattab for raising this point.